











Impressum ISSN 1867-7991 | ||
| freiesMagazin erscheint als PDF und HTML einmal monatlich. | ||
| Redaktionsschluss für die März-Ausgabe: 21. Februar 2009 | ||
| Kontakt | ||
| Postanschrift | freiesMagazin | |
| c/o Dominik Wagenführ | ||
| Beethovenstr. 9/1 | ||
| 71277 Rutesheim | ||
| Webpräsenz | http://www.freiesmagazin.de | |
| Autoren dieser Ausgabe | ||
| Martin Böcher | ZFS unter Linux | |
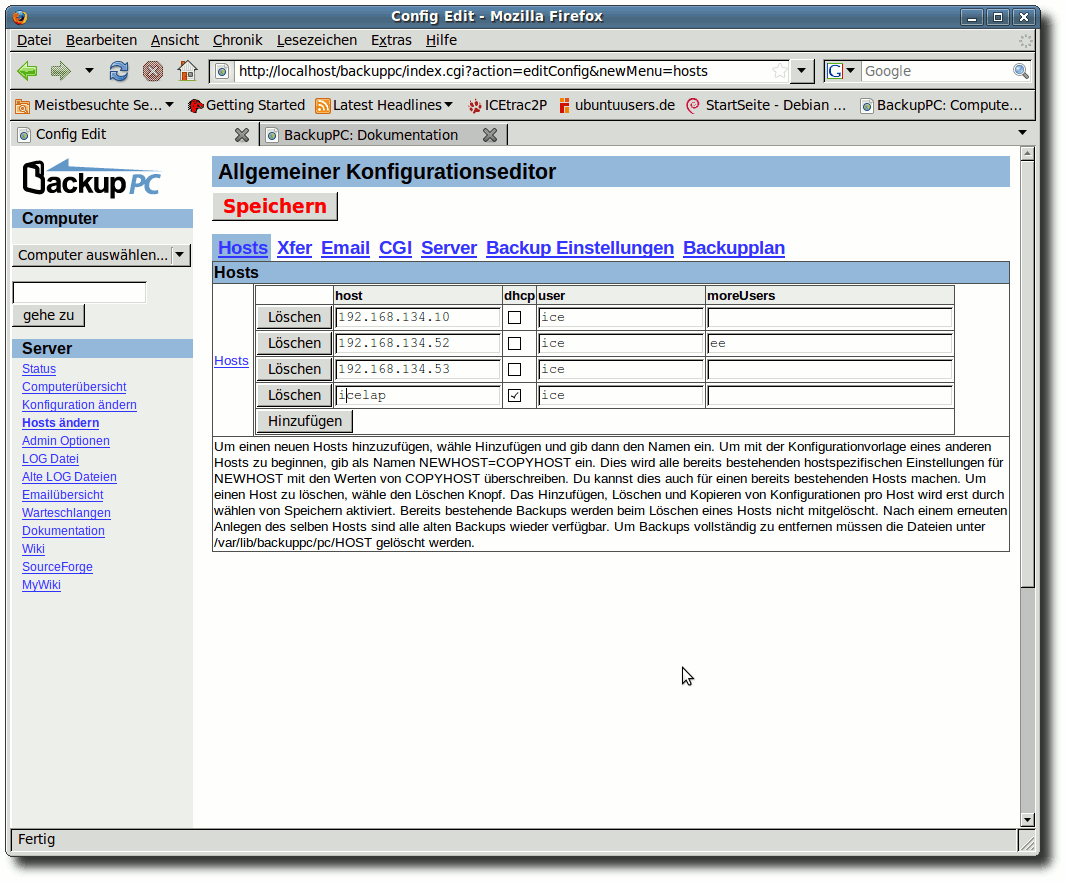
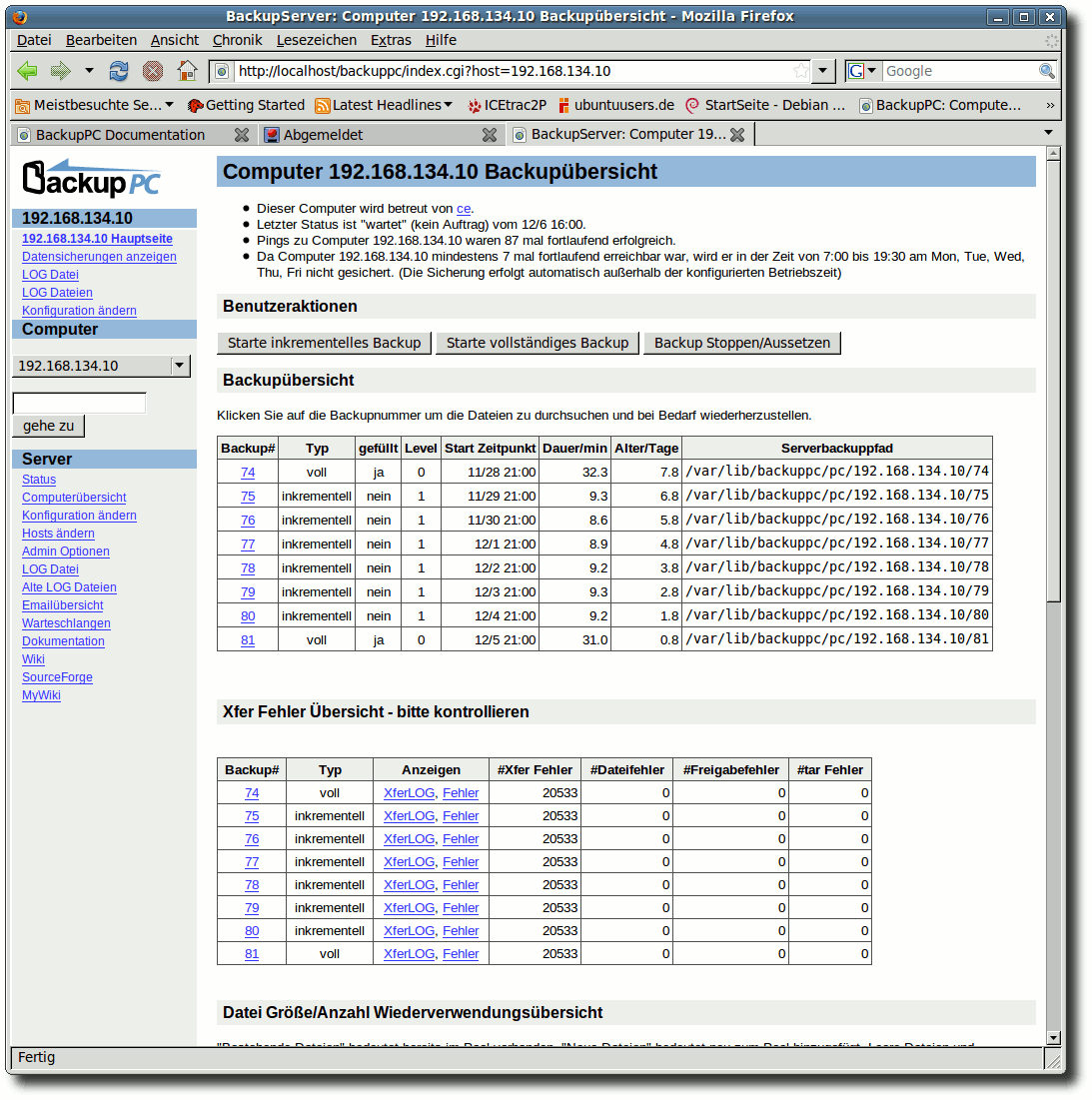
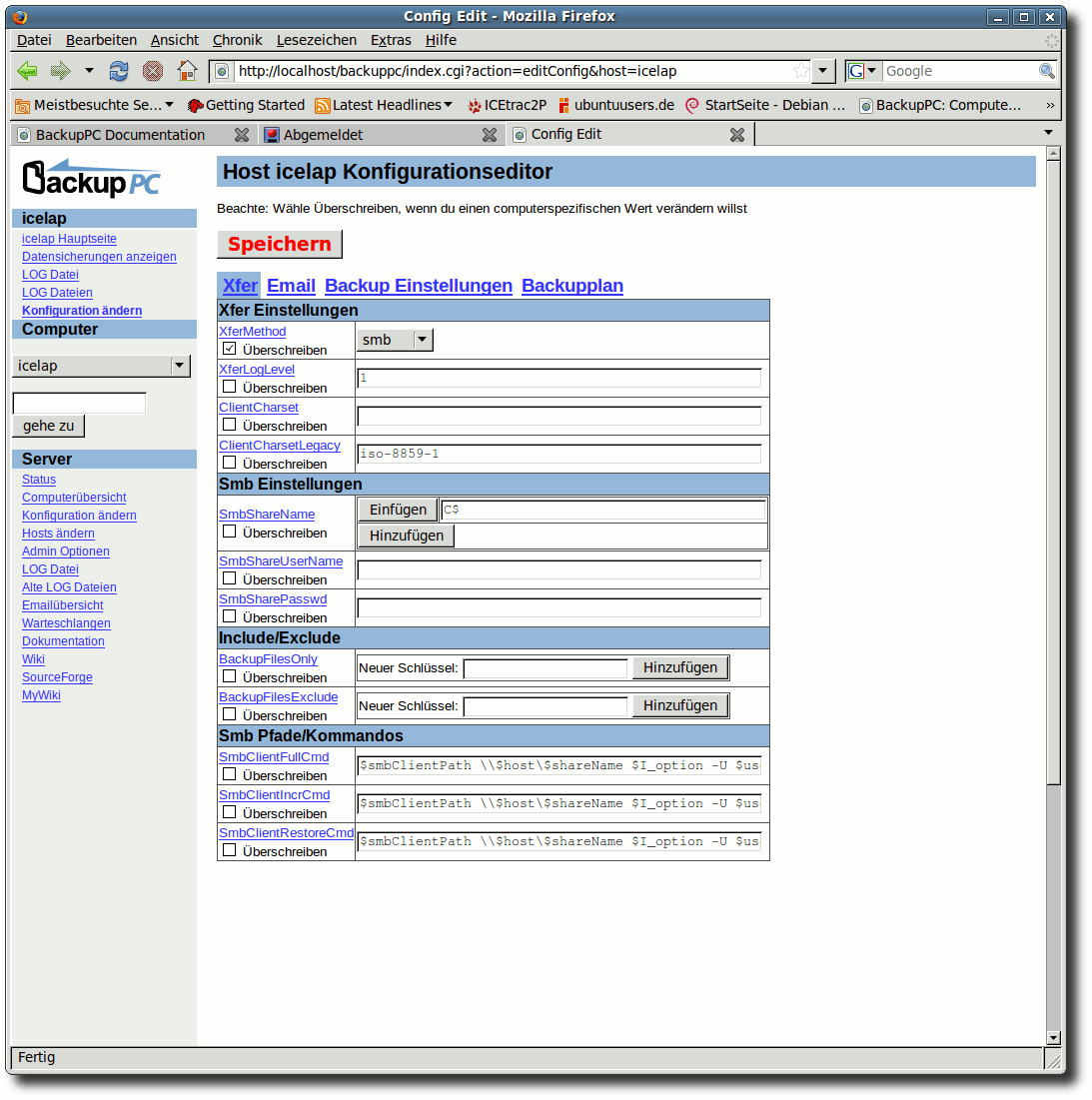
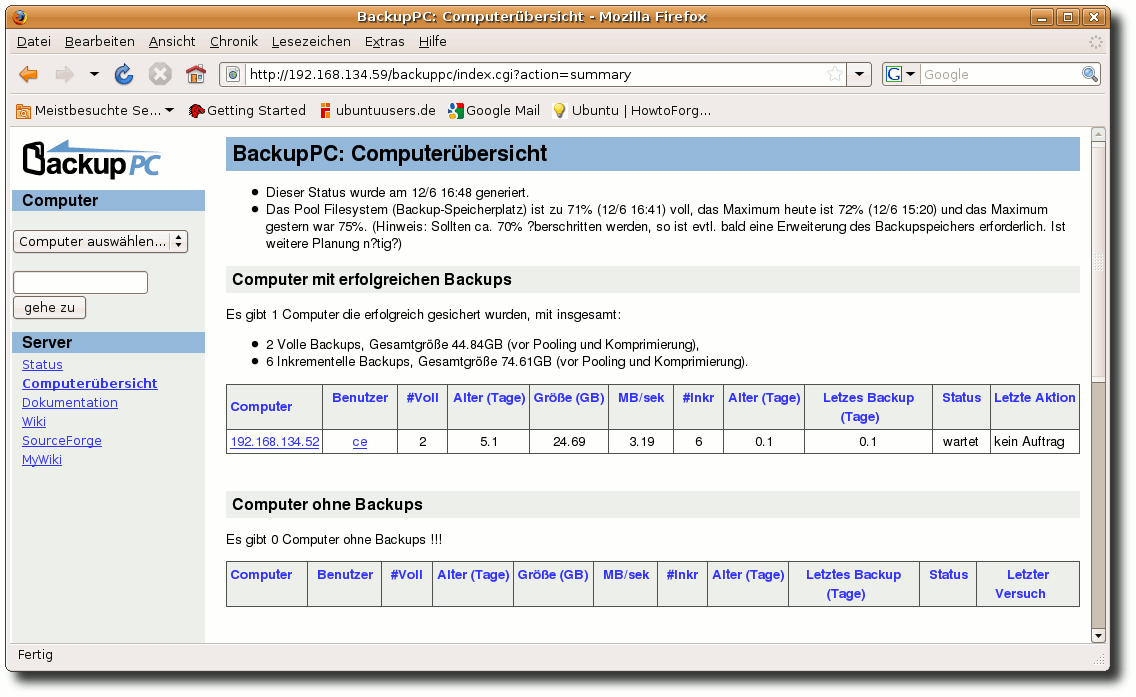
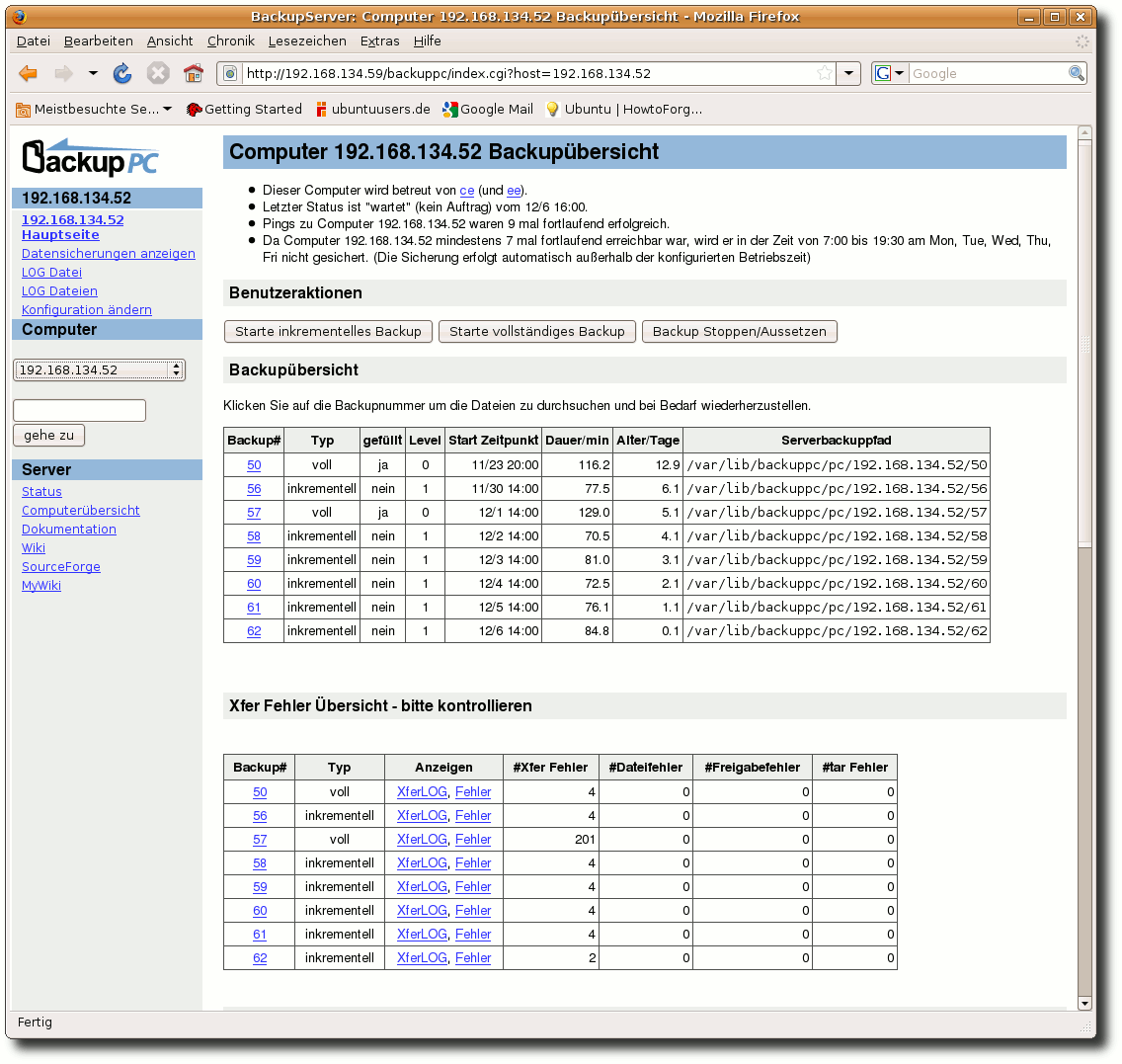
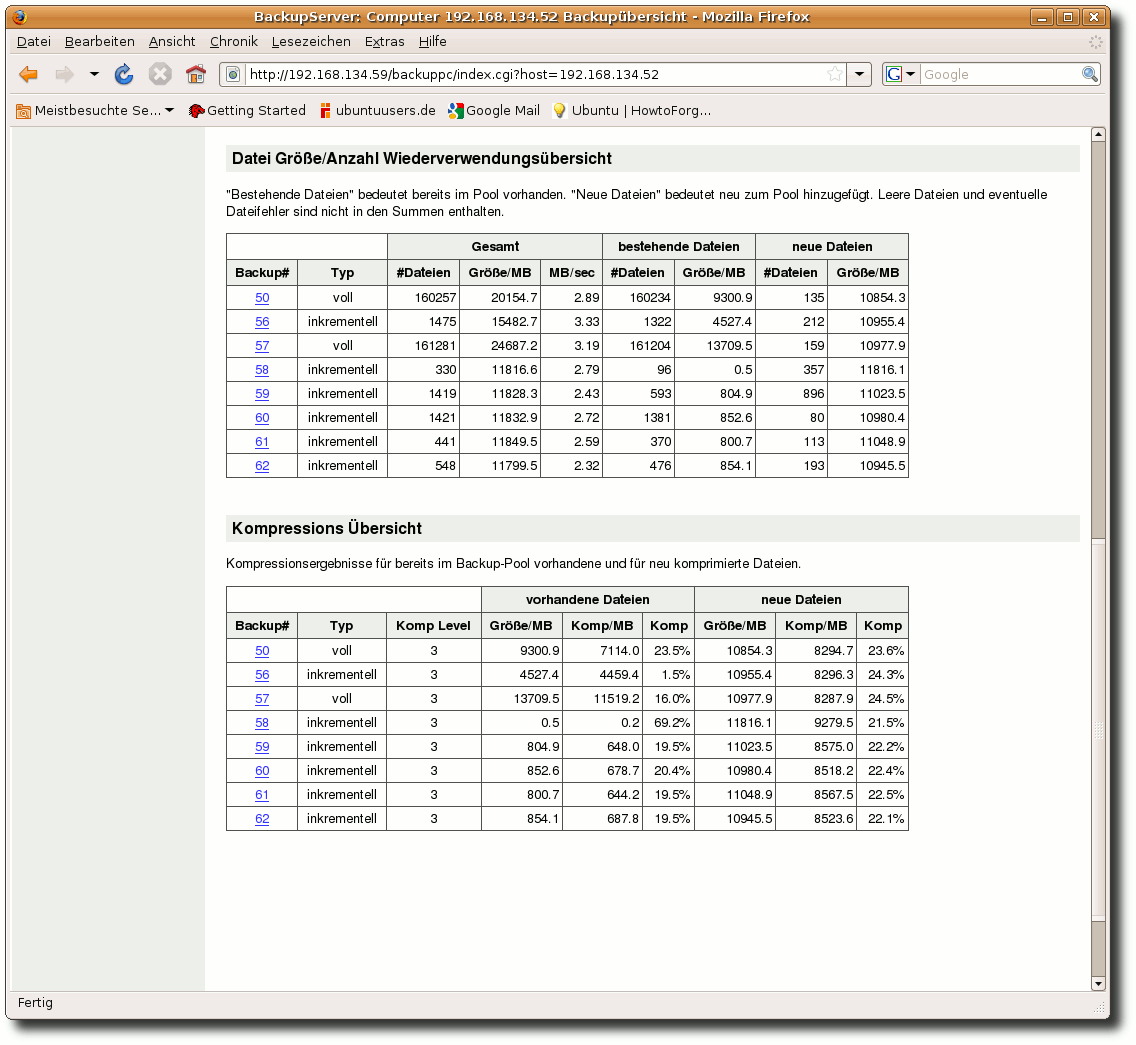
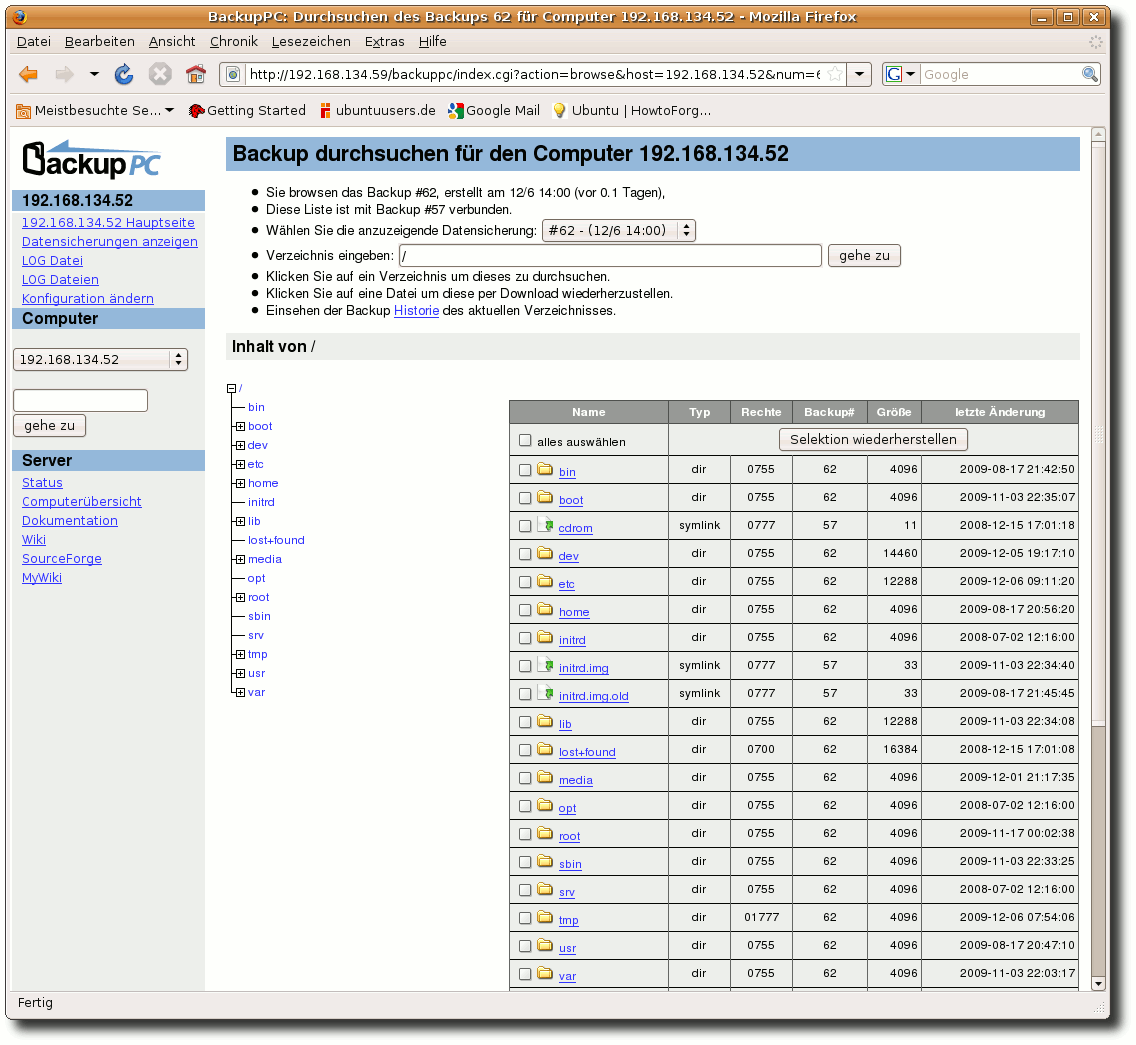
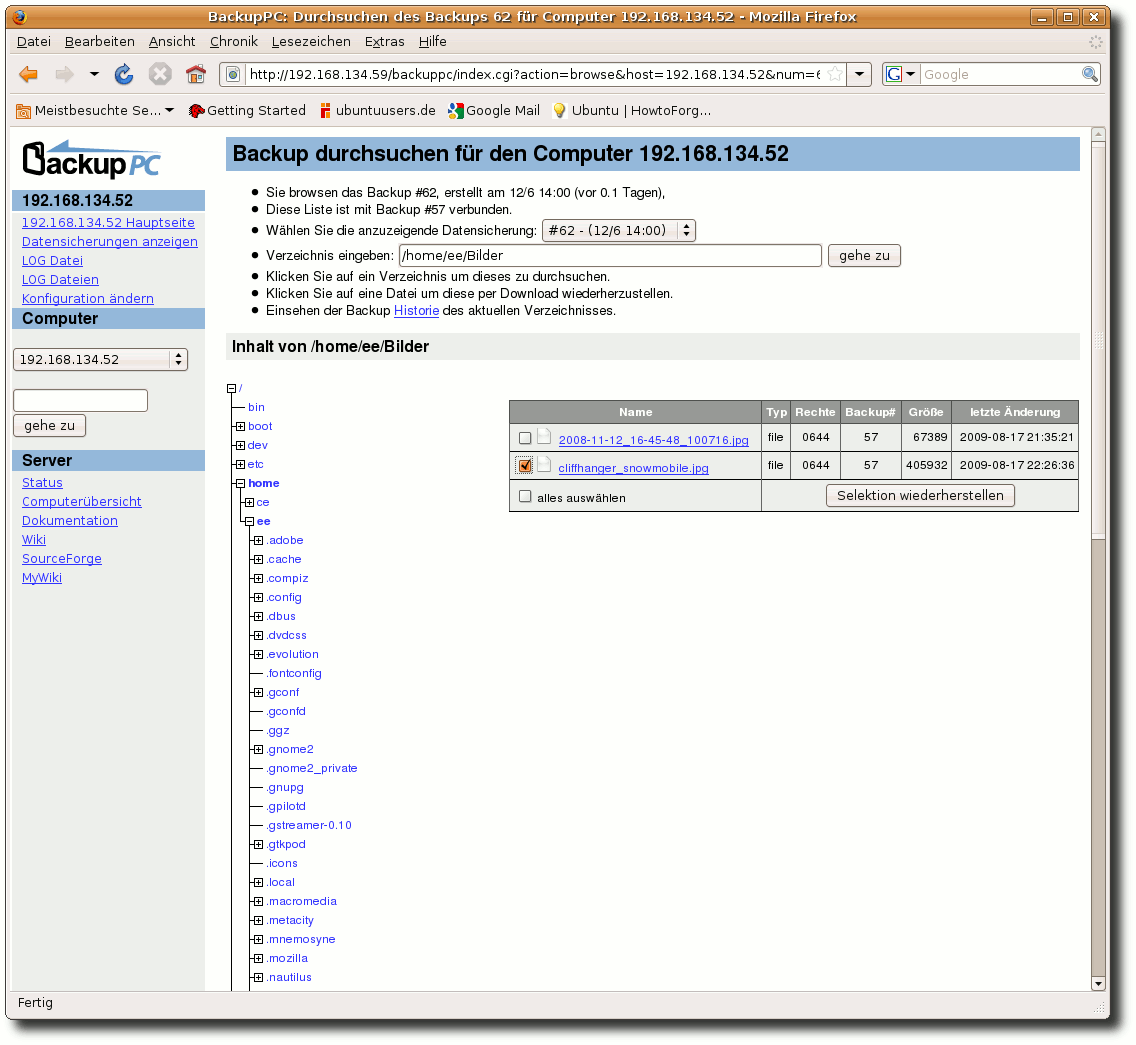
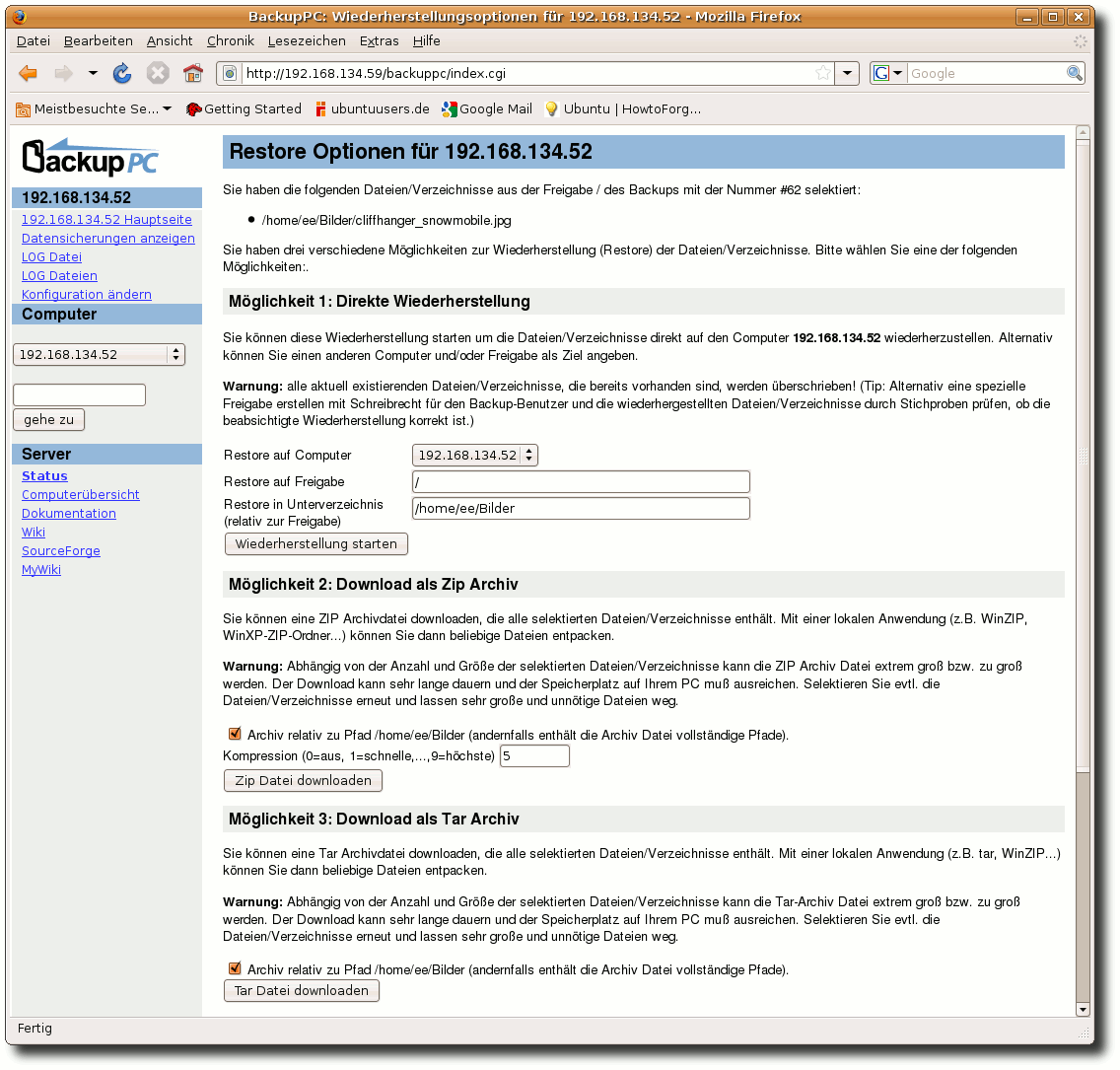
| Charles Ernst | BackupPC als Backupserver im Heimnetzwerk | |
| Jens Hevike | Eine zu bewältigende Aufgabe: Linux Professional Institute Certification | |
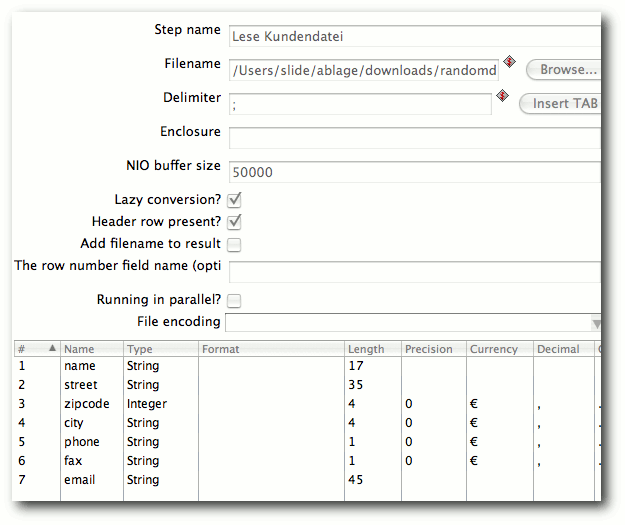
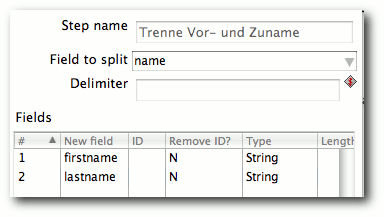
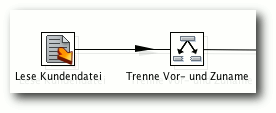
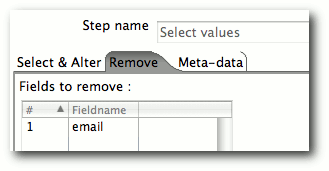
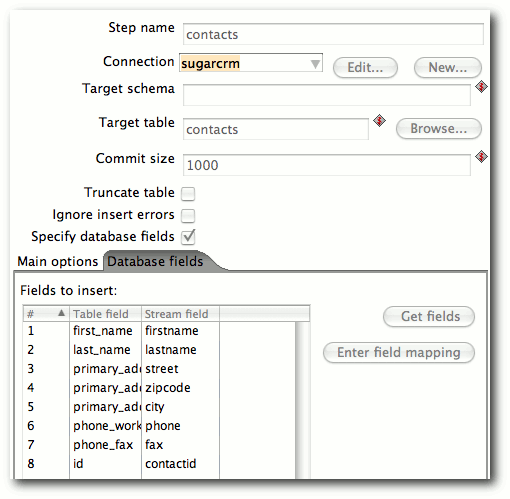
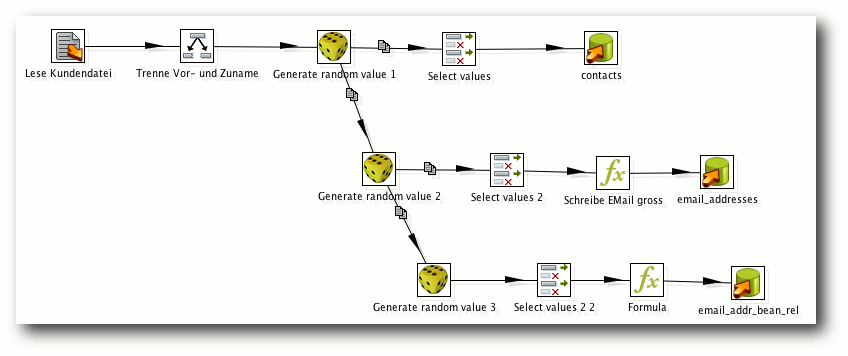
| Matthias Kietzke | Pentaho Data Integration | |
| Steve Klicek | Jamendo - Ein freier und kostenloser Musikdownload | |
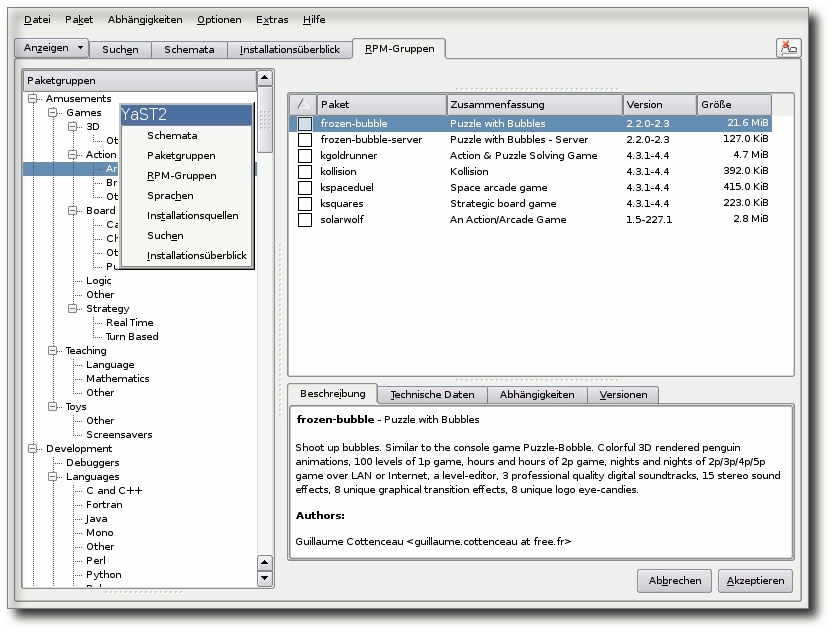
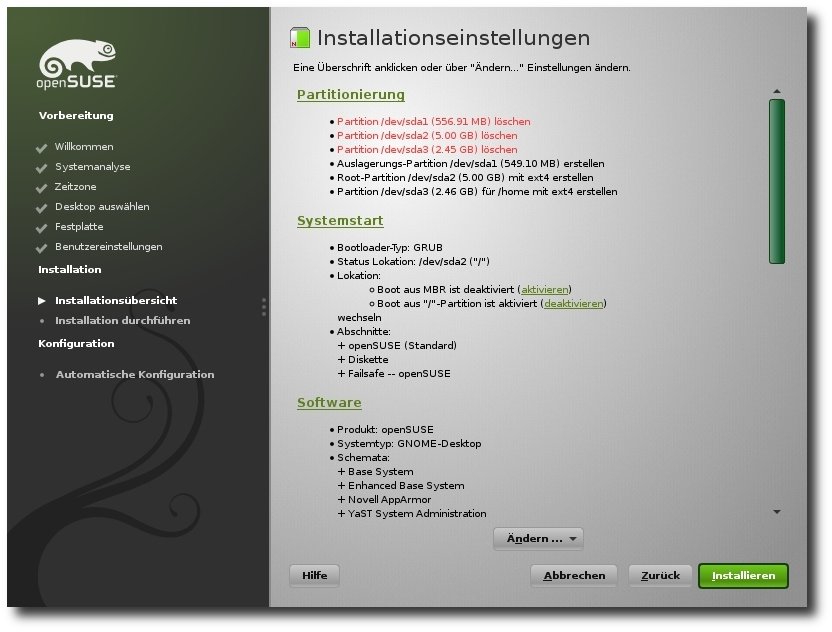
| Mirko Lindner | openSUSE 11.2 | |
| Mathias Menzer | Der Dezember im Kernelrückblick | |
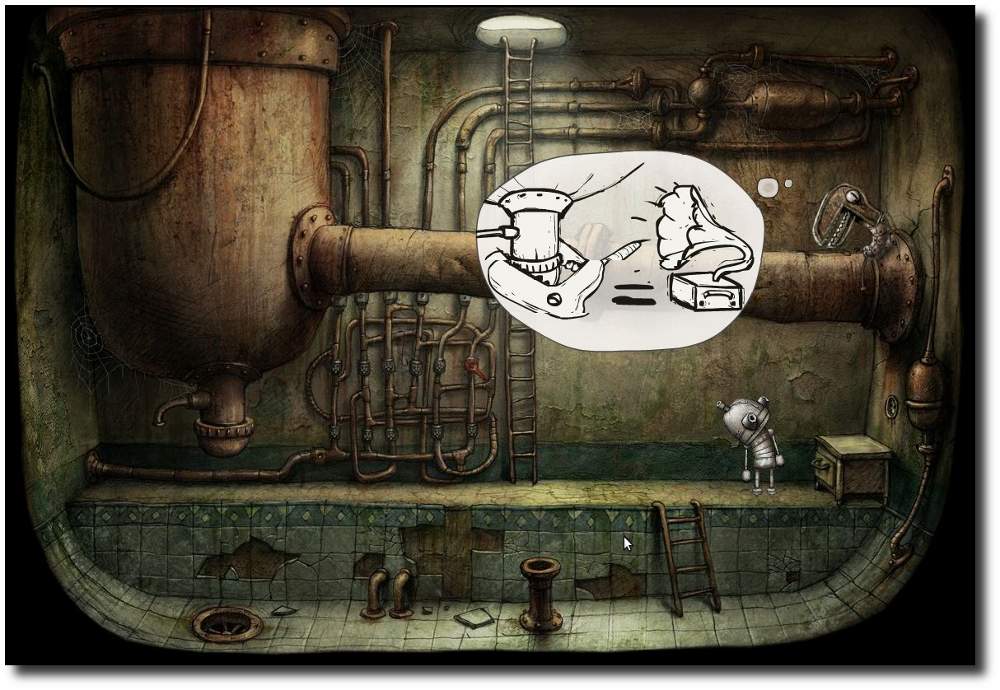
| Dominik Wagenführ | Machinarium - In der Welt der Maschinen, Das Betriebssystem GNU/Linux | |
| Erscheinungsdatum: 7. Februar 2010 | ||
| Redaktion | ||
| Dominik Honnef | Thorsten Schmidt | |
| Dominik Wagenführ (Verantwortlicher Redakteur) | ||
| Satz und Layout | ||
| Ralf Damaschke | Yannic Haupenthal | |
| Michael Niedermair | Sebastian Schlatow | |
| Korrektur | ||
| Daniel Braun | Frank Brungräber | |
| Karsten Schuldt | ||
| Veranstaltungen | ||
| Ronny Fischer | ||
| Logo-Design | ||
| Arne Weinberg (GNU FDL) | ||
Soweit nicht anders angegeben, stehen alle Artikel und Beiträge in freiesMagazin unter der GNU-Lizenz für freie Dokumentation (FDL). Das Copyright liegt beim jeweiligen Autor. freiesMagazin unterliegt als Gesamtwerk ebenso der GNU-Lizenz für freie Dokumentation (FDL) mit Ausnahme von Beiträgen, die unter einer anderen Lizenz hierin veröffentlicht werden. Das Copyright liegt bei Dominik Wagenführ. Es wird die Erlaubnis gewährt, das Werk/die Werke (ohne unveränderliche Abschnitte, ohne vordere und ohne hintere Umschlagtexte) unter den Bestimmungen der GNU Free Documentation License, Version 1.2 oder jeder späteren Version, veröffentlicht von der Free Software Foundation, zu kopieren, zu verteilen und/oder zu modifizieren. Die xkcd-Comics stehen separat unter der Creative-Commons-Lizenz CC-BY-NC 2.5. Das Copyright liegt bei Randall Munroe.
Zum Index